Can Large Language Models Predict Plant Gene Functions Accurately?
Synopsis
Discover how large language models are transforming our understanding of plant genomics! This groundbreaking study reveals the power of AI in predicting gene functions and regulatory elements, promising to enhance crop improvement and biodiversity conservation in a world facing food security challenges.
Key Takeaways
LLMs can accurately predict gene functions in plants.
They leverage similarities between genomic sequences and natural language.
Enhancements in crop improvement and biodiversity conservation are possible.
Traditional models are often limited by data availability.
Research highlights the adaptability of LLMs across species.
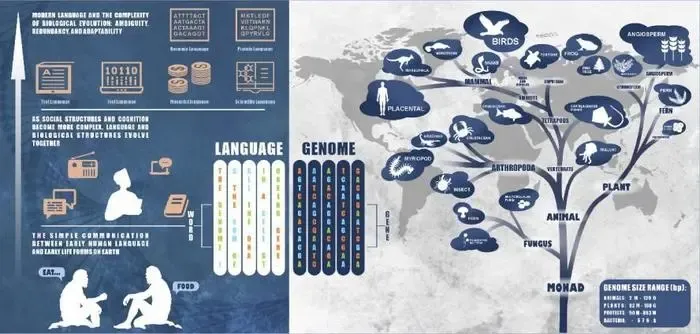
New Delhi, June 1 (NationPress) Large language models (LLMs), when trained on extensive plant genomic data, can accurately predict gene functions and regulatory elements, researchers revealed on Sunday.
By utilizing the structural similarities between genomic sequences and natural language, these AI-driven models can interpret complex genetic data, providing breakthrough insights into plant biology.
This development shows potential for speeding up crop enhancement, improving biodiversity conservation, and reinforcing food security amidst global challenges, as noted in the study published in the Tropical Plants journal.
Historically, plant genomics has struggled with the complexities of expansive datasets, often hindered by the limitations of traditional machine learning models and a lack of annotated data.
While LLMs have transformed areas like natural language processing, their use in plant genomics has been in its infancy. The main challenge has been modifying these models to understand the distinct "language" of plant genomes, which significantly differs from human linguistic structures.
This study examined the capabilities of LLMs in plant genomics.
By paralleling the structures found in natural language and genomic sequences, the research illustrates how LLMs can be trained to comprehend and predict gene functions, regulatory elements, and expression patterns in plants.
The study discusses various LLM architectures, including encoder-only models like DNABERT, decoder-only models such as DNAGPT, and encoder-decoder models like ENBED.
The research team employed a strategy involving pre-training LLMs on extensive datasets of plant genomic sequences, followed by fine-tuning with specific annotated data to increase accuracy.
By treating DNA sequences like linguistic sentences, the models could uncover patterns and connections within the genetic code.
These models have demonstrated potential in tasks such as promoter prediction, enhancer identification, and gene expression analysis. Notably, plant-specific models like AgroNT and FloraBERT have been created, showing enhanced performance in annotating plant genomes and forecasting tissue-specific gene expression.
However, the study also highlights that most existing LLMs are trained on animal or microbial data, which frequently lacks comprehensive genomic annotations, showcasing the adaptability and strength of LLMs across various plant species.
In conclusion, this research emphasizes the vast potential of integrating artificial intelligence, particularly large language models, into plant genomics studies. The research was conducted by Meiling Zou, Haiwei Chai, and Zhiqiang Xia’s team from Hainan University.
Point of View
It's essential to highlight the remarkable potential of integrating artificial intelligence into plant genomics. The findings of this research not only underscore the advancements in technology but also emphasize the vital role of these innovations in addressing global food security and environmental challenges. The collaboration of researchers exemplifies a commitment to enhancing our understanding of plant biology, making it a promising avenue for future exploration.
NationPress
4 Jul 2026
Frequently Asked Questions
What are large language models?
Large language models (LLMs) are AI systems designed to understand and generate human language, now being adapted for genomic sequences in plants.
How do LLMs predict gene functions?
LLMs analyze the structure of genomic sequences in a manner similar to natural language, allowing them to decode complex genetic information.
What are the implications of this research?
The findings could significantly accelerate crop improvement, enhance biodiversity efforts, and strengthen food security globally.
What challenges do traditional models face?
Traditional models often struggle with large and complex datasets and are limited by the availability of annotated genomic data.
Who conducted this study?
The research was conducted by a team led by Meiling Zou, Haiwei Chai, and Zhiqiang Xia from Hainan University.












