Nvidia Cuts AI Token Costs 5x With Blackwell Software Gains

Synopsis
Nvidia reports that software optimisations on its Blackwell platform improved DeepSeek V4 inference performance by up to 5x in one month, slashing token costs to roughly one-fifth of previous levels. The company says its integrated stack delivers up to 20x higher throughput on the same GPU, compounding gains across runtimes, kernels, networking, and hardware.
Key Takeaways
5x performance gain on DeepSeek V4 achieved in just one month through software optimisations on Nvidia Blackwell GPUs.
Token costs reduced to roughly one-fifth of previous levels without new hardware investment.
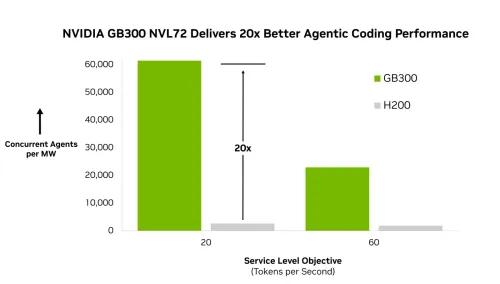
Nvidia's integrated inference stack delivers up to 20x higher throughput on the same GPU.
Improvements span runtimes, kernels, networking, and hardware — compounding over time post-deployment.
Partners Baseten, Cognition, DeepInfra, Together AI, and Cursor AI are already applying these gains for customers.
The announcement has direct relevance for India's AI infrastructure push, where inference economics are a key adoption barrier.
Chip giant Nvidia announced on Tuesday, 30 June 2026 that software optimisations on its Blackwell GPU platform have improved DeepSeek V4 inference performance by up to 5 times in just one month, cutting token costs to roughly one-fifth of previous levels. The company said its integrated inference software stack can deliver up to 20 times higher throughput on the same GPU hardware, underscoring that AI cost reduction continues well after initial infrastructure deployment.
Context
Nvidia's post states that its 'inference software keeps driving down token costs, long after AI infrastructure is deployed.' The claim centres on the Nvidia Blackwell architecture, where a single month of software-level optimisations — spanning runtimes, kernels, networking, and hardware — produced a 5x performance uplift on DeepSeek V4, one of the most widely benchmarked open-weight large language models. The company highlighted that improvements compound across the entire stack, not just at the chip level.
Nvidia's inference software stack is described as 'co-designed with NVIDIA GPUs, CPUs, networking, and systems' and powered by CUDA-native open source frameworks. The company says this tight integration ensures that new model breakthroughs and optimisations are available on Nvidia hardware 'from day zero,' with throughput continuing to improve and costs continuing to fall post-deployment.
Policy Backdrop
The announcement arrives at a moment when AI inference costs have become a central concern for enterprises, cloud providers, and governments planning large-scale AI deployments. Reducing the cost per token directly lowers the barrier for deploying AI at scale — a factor that has significant implications for India's national AI mission and the broader push by Indian startups and public-sector bodies to build cost-effective AI infrastructure. The IndiaAI Mission, which aims to make sovereign AI compute accessible, has repeatedly flagged inference economics as a bottleneck for widespread adoption.
Globally, the race to reduce inference costs has intensified since the release of efficient models such as DeepSeek V3 and V4, which demonstrated that smaller, well-optimised models can rival larger ones. Nvidia's framing — that software, not just silicon, is the primary lever for cost reduction — positions the company as an ongoing partner rather than a one-time hardware vendor.
Stakeholders and Impact
Nvidia specifically named five inference and developer-platform companies — Baseten, Cognition, DeepInfra, Together AI, and Cursor AI — as partners translating 'continuous software innovation into lower cost per token.' These firms serve a broad range of customers, from enterprise software developers to AI-native startups, meaning the cost reductions have downstream effects across the AI application layer. Lower token costs can make AI-powered products more viable for price-sensitive markets, including India, where per-query economics are a decisive factor for consumer and SME adoption.
For Indian cloud and AI infrastructure players, the announcement signals that choosing Nvidia's ecosystem carries a compounding software dividend — a consideration that could influence procurement decisions by government bodies, large enterprises, and startups alike. It also raises the competitive bar for alternative GPU providers who do not offer an equivalent integrated software stack.
What's Next
Nvidia's emphasis on continuous post-deployment improvement suggests the company intends to use software cadence as a competitive moat alongside its hardware roadmap. As Blackwell-generation GPUs become more widely deployed through 2026 and into 2027, the pace of software-driven cost reduction will be closely watched by hyperscalers, AI labs, and national compute programmes. If the 5x performance gain achieved in one month on DeepSeek V4 is representative of a broader trend, enterprises that have already invested in Nvidia infrastructure stand to see significant returns without additional capital expenditure — a dynamic that could reshape how AI infrastructure ROI is calculated across the industry.
Point of View
Nvidia is directly countering the narrative that open-weight, efficient models erode the need for premium GPU infrastructure. For policymakers in India and other emerging markets designing national AI compute strategies, this changes the calculus: the true cost of inference is not fixed at procurement but falls over time within the Nvidia ecosystem. The long-term implication is that software moats, not just silicon, will determine which AI infrastructure providers dominate the next phase of the global AI build-out.
NationPress
30 Jun 2026
Frequently Asked Questions
How much did Nvidia reduce AI token costs on Blackwell?
Nvidia reduced token costs to roughly one-fifth of previous levels — a roughly 5x improvement — through software optimisations on its Blackwell GPU platform, achieved within a single month for DeepSeek V4 inference workloads.
What is Nvidia Blackwell and why does it matter for AI?
Nvidia Blackwell is the company's latest GPU architecture, designed for high-performance AI training and inference. It matters because Nvidia's integrated software stack, co-designed with Blackwell hardware, enables continuous post-deployment performance improvements that lower the cost of running AI models over time.
What is DeepSeek V4 and how does Nvidia's software help it?
DeepSeek V4 is a large language model that has become a key benchmark for inference efficiency. Nvidia's inference software stack optimised DeepSeek V4 performance by up to 5x on Blackwell GPUs in one month, reducing the cost per token significantly for companies running the model.
Which companies are using Nvidia's inference software stack?
Nvidia cited Baseten, Cognition, DeepInfra, Together AI, and Cursor AI as partners actively using its inference software stack to deliver lower cost per token to their customers.
Does Nvidia's 20x throughput claim mean I need fewer GPUs?
Nvidia's claim of up to 20x higher throughput on the same GPU means existing hardware can handle significantly more inference requests without additional capital expenditure, effectively reducing the cost per query for operators who have already deployed Nvidia infrastructure.